AlexNet 笔记
1. ReLUs (Rectified Linear Units)
f(x)=max(0,x)
考虑到梯度下降的效率问题,传统的 sigmoid 和 tanh 激活函数的计算比较费时,而且要是每一层不做正则化的话,随着层数的增加,神经元的输出会越来越大,而这两个激活函数又是饱和的,导致激活后的输出差距不大,没有区分度。
而 ReLU 则比较简单,并且效果更好,不是饱和的激活函数,所以本文中选用的是 ReLUs 作为激活函数。
2. LRN (Local Response Normalization)
LRN 的目的是增强那些有输出的神经元的影响力,达到防止过拟合的效果。
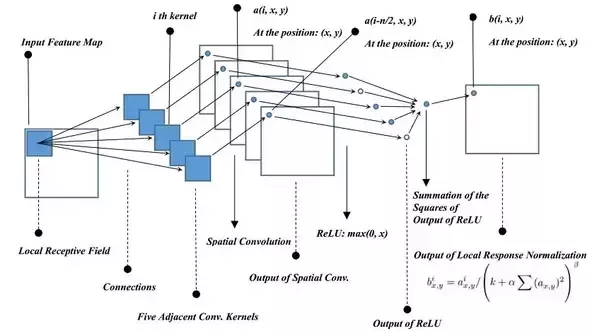
bix,y=aix,y/(k+αmin(N,i+n/2)∑j=max(0,i−n/2)(ajx,y)2)β
a: 尚未正则化的、原始(经过卷积、ReLU 层)的输出。
b: 经过 LRN 之后的输出。
i: 第 i 个 Channel。
x: 第 i 个 Channel 上的 x 坐标。
y: 第 i 个 Channel 上的 y 坐标。
N: Channel 的总数。
k: 超参数,一般设置为 2 。
α: 超参数,一般设置为 10−4 。
β: 超参数,一般设置为 0.75 。
公式的直观理解就是,对于一个 Channel 的某个像素点,找到与之邻近的 n 个 Channel 上的相同位置的像素点,做正则化(归一化)。
下图很直观地表示了计算的过程。
3. Overlapping Pooling
池化层(Pooling Layer)在 CNN 当中的作用是对卷积层的输出进行总结归纳,减少噪声的影响,突出最有价值的元素,提升模型的泛化能力,降低计算复杂度。
传统的池化层的池化单元是不重叠的,假设池化单元的尺寸为 z×z ,则池化单元的步长 s 通常取 s=z ,即正好不重叠。
论文显示,若取 z=3,s=2 ,对于 Top-1 和 Top-5 的错误率分别能降低 0.4% 和 0.3% ,同时稍微能避免模型的过拟合。
4. Overall Architecture
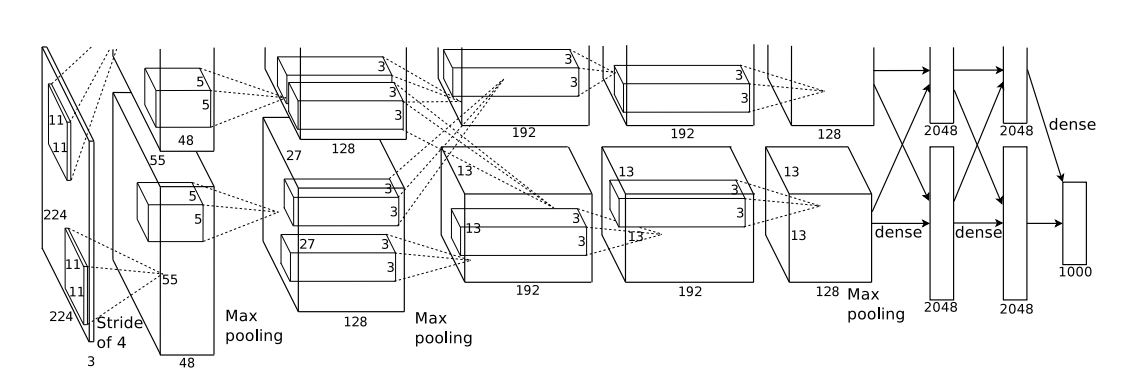
整个神经网络一共有 8 层,前 5 层是卷积层(Convolutional Layers),后 3 层是全连接层(Fully-Connected Layers),最后一层的全连接层后面连的是一个 Softmax 层,用于将全连接层的输出转化成各个图片种类的概率分布。
由于 AlexNet 使用的是两个 GPU 来训练,所以对神经网络的结构也做了一定的调整。
各种层的具体排布为:
第 2、4、5 层卷积层分别只与其上一层在同一个 GPU 的 Feature Maps(Channels)连接(而不是理想中那样的与上一层所有 Channels 都连接)。
第 3 层与两个 GPU 中的第 2 层输出的 Channels 都有连接。
所有全连接层与其前一层的所有神经元输出都有连接。
LRN(Local Response Normalization)层只接在第 1、2 层卷积层的 ReLU 输出之后。
重叠的池化层(Overlapping Pooling)接在两个 LRN 层和第 5 层卷积层之后。
ReLU 层接在每个卷积层和全连接层之后。
各层的尺寸:
输入尺寸:224×224×3
第 1 层卷积层:96×(11×11×3)
第 2 层卷积层:256×(5×5×48)
第 3 层卷积层:384×(3×3×256)
第 4 层卷积层:384×(3×3×192)
第 5 层卷积层:256×(3×3×192)
可以看到,第 2 层之后的卷积层的 Channel 的尺寸(即最后一个值 48、256、192、192),除了第 3 层的 256 与前一层的第 1 个值相同,其余都是前一层的 $1⁄2$ 。也表明了除了第 3 层与前层两个 GPU 的输出都有连接外,其它层都只与前层同一个 GPU 的输出相连接。
- 所有的全连接层的神经元个数都是 4096 。
5. Reducing Overfitting
Data Augmentation
增加训练集的图片样本数,包括对图片的平移和水平翻转。还有改变图片的 RGB 值的相对强度。
先对整个训练集进行 PCA,即进行特征值分解,得到特征值 pi 和特征向量 λi ,然后每张图片加上:
[p1,p2,p3][α1λ1,α2λ2,α3λ3]T
其中 αi∼N(0,0.12) 。
改变 RGB 的相对强度并不会改变图像的 identity,但是会突出图像的比较重要的部分。
Dropout
训练时,在全连接层上,以 0.5 的概率将某些神经元的输出设置成 0 ,也就是说该神经元不参与此次 Forward 的过程(同时也不会参与此次 Backward Propagation 的过程)。如此一来,每一次 Forward 和 Backward,其通过的神经网络的 Architecture ,与上一次都可能是不同的。
用这种方法,强制使得神经元不能去固定地依赖前面的某个输出,强迫其学习到更加 Robust 的特征,避免过拟合。